[Cloud] - Stock Market Data Analysis with Kafka
Stock Market Data Analysis with Kafka
Overview: Developed a system utilizing Apache Kafka on AWS EC2 to simulate and analyze real-time stock market data streams. This setup integrates various AWS services to ensure efficient data processing, storage, and querying.
Experiment referenced from this <tutorial>.
Code in the Project can be found (here)
Architecture:
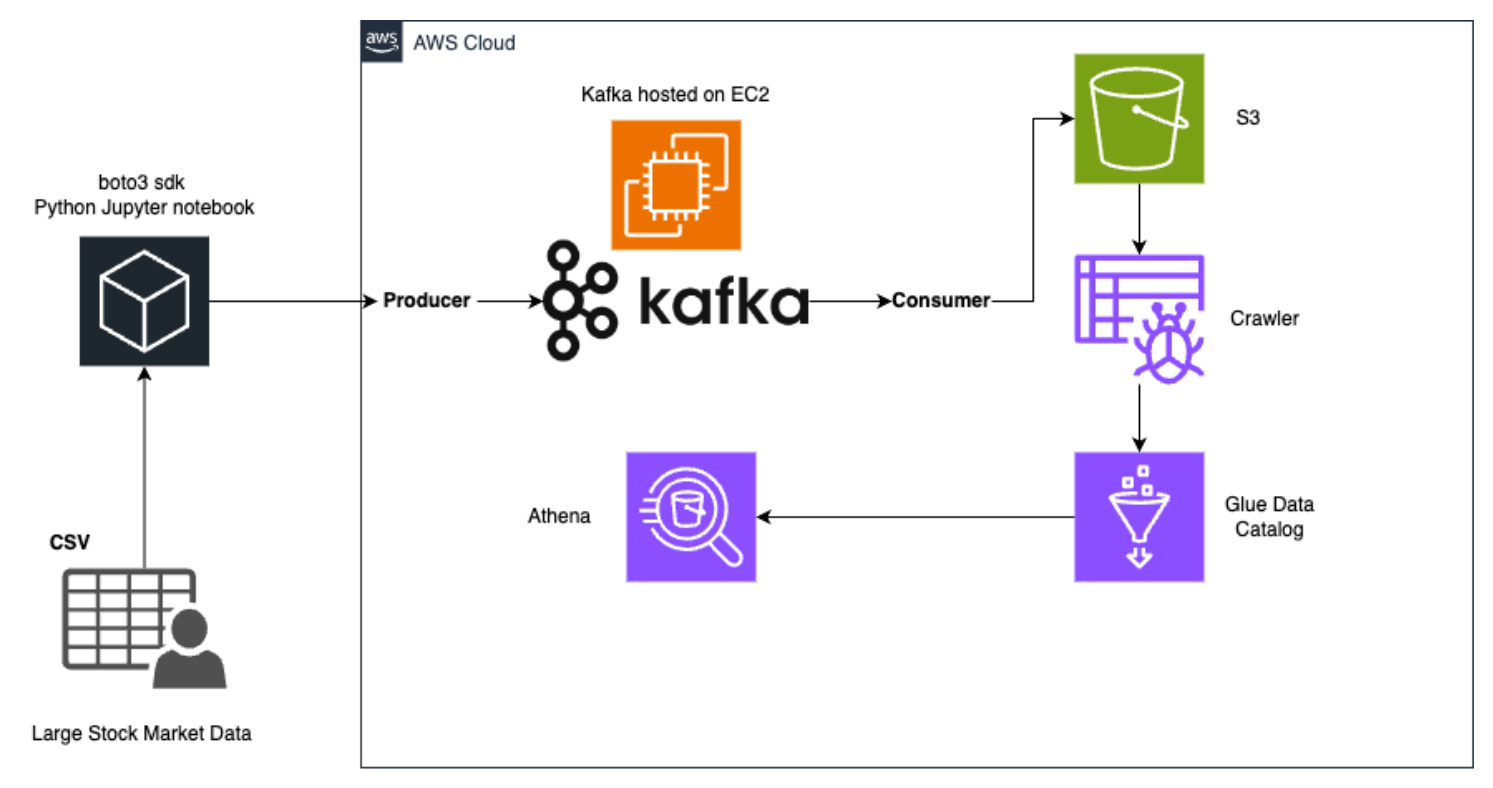
- Producer:
- Stock Market App Simulation: Generates and simulates real-time stock market data.
- SDK Boto3: Utilized for interfacing with AWS services.
- Apache Kafka: Acts as the backbone for streaming the data. Producers publish the generated data into Kafka topics, hosted on an EC2 instance.
- Consumer:
- Amazon S3: Consumers read the streamed data from Kafka and store it in Amazon S3 for persistent storage.
- AWS Glue: Used for ETL (Extract, Transform, Load) processes. The Glue Crawler scans the data stored in S3 and updates the AWS Glue Data Catalog with the schema and metadata.
- Data Processing & Analysis:
- AWS Glue Data Catalog: Centralized metadata repository to hold the schema information, making it easy to query and analyze data.
- Amazon Athena: Provides serverless SQL querying capabilities on the data stored in Amazon S3. Athena utilizes the metadata stored in the Glue Data Catalog for efficient data querying and analysis.
Workflow:
- The Producer component simulates real-time stock market data using a stock market app.
- The data is sent to Kafka topics via Apache Kafka producers running on AWS EC2.
- Kafka Consumers then read this streamed data and store it in Amazon S3 buckets.
- AWS Glue crawlers process the data stored in S3, updating the Glue Data Catalog with the necessary schema information.
- Using Amazon Athena, the stored data can be queried and analyzed efficiently, leveraging the metadata from the Glue Data Catalog.
Benefits:
- Real-time Data Processing: Kafka allows handling real-time data streams, making it suitable for stock market simulations and analyses.
- Scalability: The architecture is designed to scale with the volume of data, ensuring reliable performance even with large datasets.
- Serverless Analysis: AWS Glue and Athena provide powerful ETL and querying capabilities without the need to manage underlying infrastructure.
- Cost-efficiency: Using serverless services like Glue and Athena helps in reducing operational costs while maintaining high efficiency.